From Base to Reasoning Model: A Full Post-Training Pipeline on a Single Node
Shamane Siri
March 2026
Post-training pipelines can now turn base models into capable reasoning assistants with far less overhead than many still assume. Historically, this work required not only compute, but also mature recipes, carefully curated data, multiple training stages, and substantial engineering effort. Meta's Llama 3.2 Instruct models were released before the current wave of progress in open post-training had fully taken shape. Our goal was to follow these newer open recipes in a practical setting and see how far they can now push a Llama 3.2 3B base model.
What this shows is how quickly open post-training has matured. In a short time, improvements in recipes, data, and training methodology have made strong post-training far more practical and reproducible. Using an open recipe inspired mainly by SmolLM3 style training, we reproduced the core stages of modern post-training (mid-training, supervised fine-tuning, preference optimization, and reinforcement learning) on a single compute node with one researcher in a matter of weeks. The broader takeaway is encouraging: sophisticated post-training is much more accessible, and open methods are advancing fast enough to close gaps that previously seemed out of reach.
Background#
LLMs have recently achieved remarkable gains by applying a post-training pipeline on top of base models. Projects like Hugging Face's SmolLM3 (3B model) and Allen AI's OLMo 3 (7B/32B models) demonstrate that sequential fine-tuning stages can transform a base model into a much more capable instruct and reasoning model [1,2]. These pipelines typically involve:
- An intermediate large scale mid-training on curated data to inject new skills, that consists of reasoning traces and instructions.
- Supervised fine-tuning (SFT) on instruction-following demonstrations.
- Preference optimization (e.g. Direct Preference Optimisation (DPO), Anchored Preference Optimisation (APO)) using chosen and rejected pairs.
- Reinforcement learning (RL) on complex reasoning tasks for further improvement.
Inspired by these recipes, we set out to apply the full post-training stack to Meta's Llama-3.2-1B [3] and elevate it towards the quality of its instruct-tuned version (Llama-3.2-1B-Instruct [4]). Our goal was to reproduce the multi-stage post-training flow on a smaller model to validate how each stage contributes to performance gains. In doing so, we followed the blueprint from SmolLM3 [1], adapting it to our infrastructure and budget constraints.
Experiment Setup#
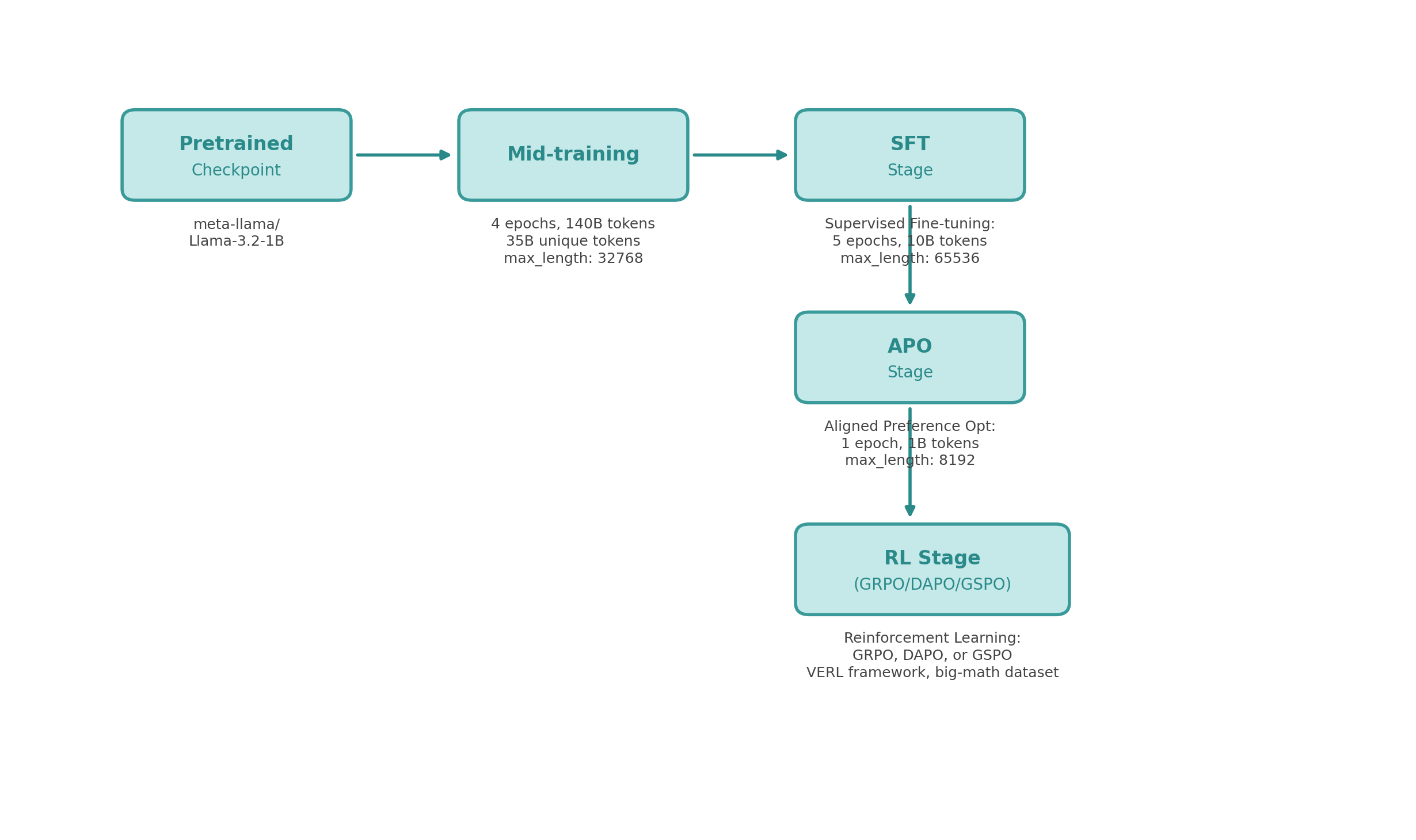
We initialized with the Llama-3.2-1B base model and first modified its tokenization to be ChatML template (a structured prompt format used in SmolLM3's chat template) friendly. Although the base Llama-3.2-1B model can support extended contexts up to ~128K tokens with long-context adaptations, most of the mid-training, SFT, and alignment stages were conducted using shorter context lengths to match the training setup. This involved mapping unused special tokens to the special tokens that appear in the ChatML format so that the model could easily ingest conversation-style prompts. We then executed four stages of training in sequence – Mid-Training, SFT, APO, and RL – using appropriate frameworks for each:
- TRL (Transformers Reinforcement Learning) library [5] for Mid, SFT and preference tuning, leveraging built-in trainers and DeepSpeed ZeRO-3 for efficient training.
- VeRL (ByteDance's open RL framework) [6] for the RL stage, which integrates Ray and PyTorch FSDP to manage large-scale rollout generation and policy optimization.
We fixed a compute budget corresponding to a single node p4d.24xlarge GPU (8 × 40G A100 GPUs) throughout all stages. Keeping the hardware fixed allowed us to plan memory usage and wall-clock time precisely for different context lengths and batch sizes. Each intermediate stage produced a new model checkpoint so that we could evaluate progress incrementally. Below, we describe each stage, the data used, and the observed impact on the model's capabilities.
Evaluation Benchmarks#
We evaluated our models at each stage using a suite of benchmarks targeting different capabilities:
- GSM8K (Grade School Math 8K): Tests multi-step arithmetic reasoning with word problems requiring 2–8 steps. We use extractive_match which checks if the final numerical answer appears correctly in the model's output.
- GSM Plus: A harder variant of GSM8K with additional distractor information and more complex problem structures, testing robustness of mathematical reasoning.
- GPQA Diamond (Graduate-Level Google-Proof QA): Expert-level science questions (biology, physics, chemistry) designed to be unsearchable—tests genuine reasoning and knowledge synthesis. We report pass@k=1 (single-attempt accuracy).
- IFEval (Instruction Following Evaluation): Measures how well models follow specific formatting and constraint instructions (e.g., “respond in exactly 3 sentences”, “use bullet points”). We report prompt_strict_acc which requires exact compliance with all constraints.
These benchmarks collectively assess: basic reasoning (GSM8K), robust reasoning (GSM Plus), advanced knowledge synthesis (GPQA), and instruction compliance (IFEval).
Stage 1: Reasoning Mid‑Training#
The first stage was the “mid-training” designed to inject the base model with general instruction following and reasoning skills before any solid supervised instruction tuning. This concept mirrors what SmolLM3 and OLMo3 did – a targeted additional pre-train on long, short, and reasoning-intensive data to improve the model's core capabilities. We use SmolLM3's mid-training corpus [7] of high-quality tokens focusing on domains like math, code, and logic.
We followed the chat template given in the SmolLM3 recipe [8]. The major part to notice was, this chat template was a minimal one with both thinking and non-thinking models. The mid-training was run for multiple epochs over ~35B tokens (4-epoch mid-training on 140B tokens). The context window was set to 32768 tokens as it was fitting to our GPU setup. Our mid-training config with the TRL library can be found here.
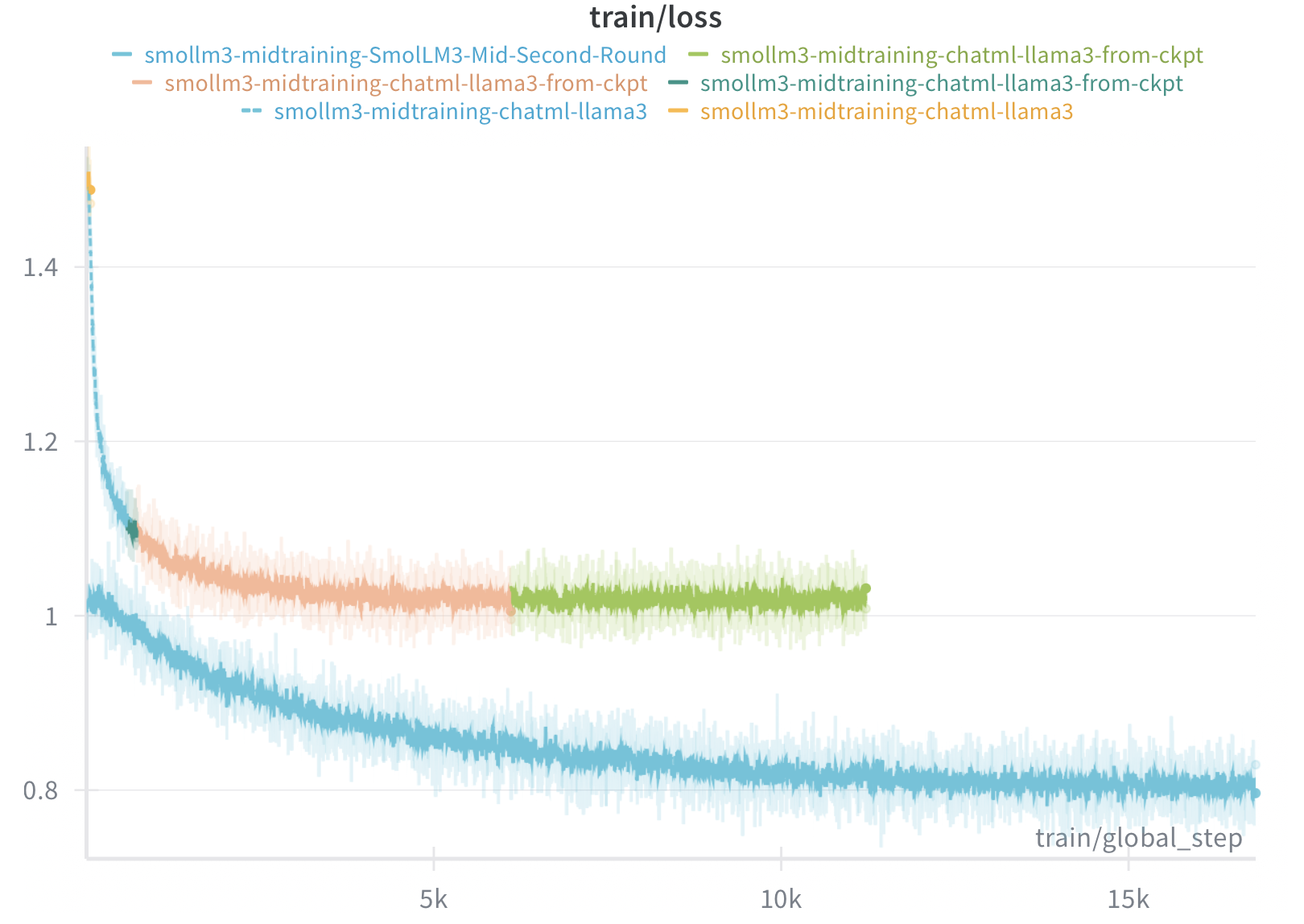
The mid-training loss curve reveals several important dynamics. The initial steep drop from ~1.4 to ~1.0 within the first 5K steps indicates rapid adaptation to the new data distribution. The different colored lines represent separate training runs—we initially trained for two epochs (reaching ~10K steps), paused to evaluate downstream stages, then continued for two additional epochs. The initial two-epoch run was conducted primarily to quickly validate the training pipeline, as mid-training is the most time-consuming stage of the overall process. The second round was initialized from the checkpoint obtained after the initial two epochs and continued training for additional epochs, which explains why its loss continues to decrease while the first run appears to plateau.
After the Mid-training, we compared it with the base model on the following metrics. Mid-training clearly improved the base model's reasoning and long-context handling. The following evaluation metrics show how mid-training improves the instruction following capabilities as well as reasoning capabilities.
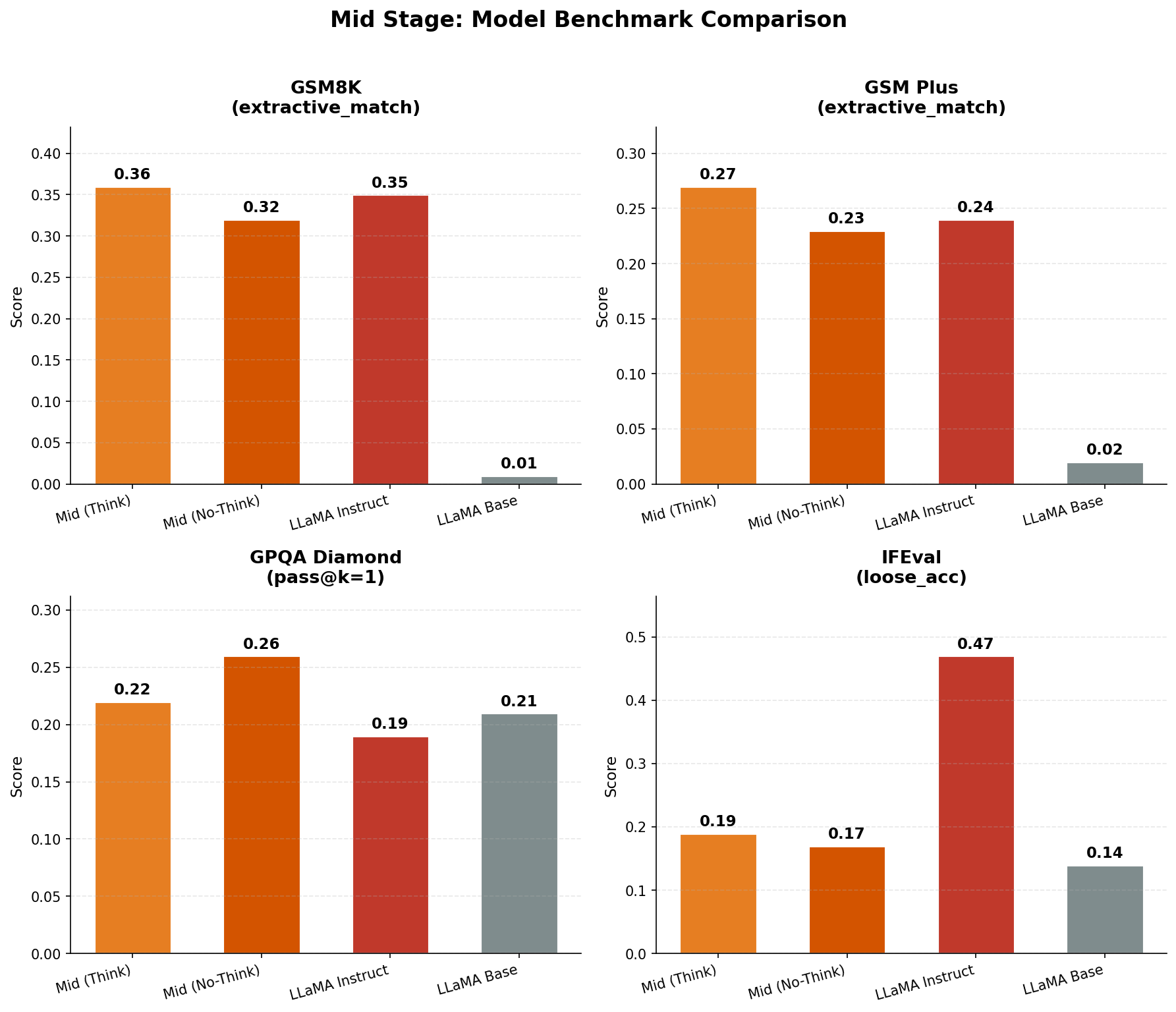
Benchmark Analysis: Looking at the benchmark comparisons:
- Math robustness clearly moved: GSM8K and GSM-Plus jump sharply in Think mode (e.g., GSM8K ~0.02 → ~0.34; GSM-Plus ~0.03 → ~0.26), which is consistent with the mid-training mix being math-heavy.
- Instruction following only nudged: IFEval improves slightly (~0.13 → ~0.15), so mid-training alone doesn't “teach compliance,” it mostly shifts priors.
- GPQA barely moves: small uplift (~0.23 → ~0.26) suggests limited gains in scientific knowledge/synthesis at 1B, and improvements may be prompt/template effects rather than capability.
Stage 2: Supervised Fine‑Tuning (SFT)#
With a stronger base model in hand, we moved to supervised fine-tuning, where the model learns to follow instructions and engage in helpful dialogue. As above we used the SmolLM3 SFT dataset [9] which was a blend of instruction-following demonstrations and chat conversations, covering skills like open QA, multi-turn dialogue, tool use (e.g. function calling), coding assistance, and multi-step reasoning.
We also managed to use a 65K context window. An important aspect related to the chat template was, compared to the Mid-training template, this chat template has more special tokens related to coding and tool calling. Again, similar to mid-training, SmolLM3 SFT datasets consist of both thinking and non-thinking examples. After about 4 epochs over ~2.5B tokens (≈10B token instances after packing) of SFT data, we obtained the SFT version. The SFT training configs can be found here.
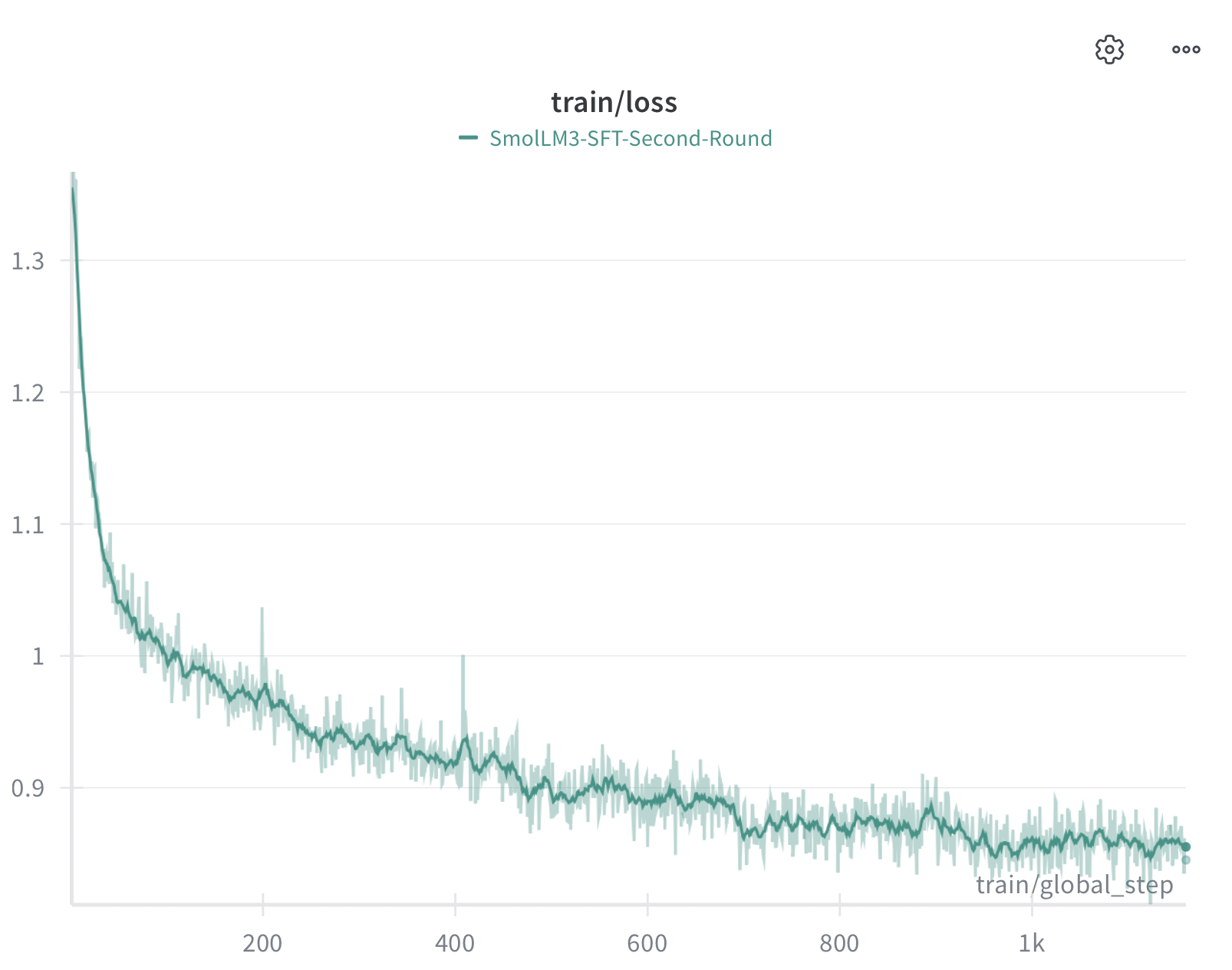
The SFT training loss shows a smooth, monotonic decrease from ~1.3 to ~0.85 over approximately 1K steps. The relatively noise-free curve indicates stable optimization, likely due to the high-quality curated nature of the SmolLM3 SFT dataset.
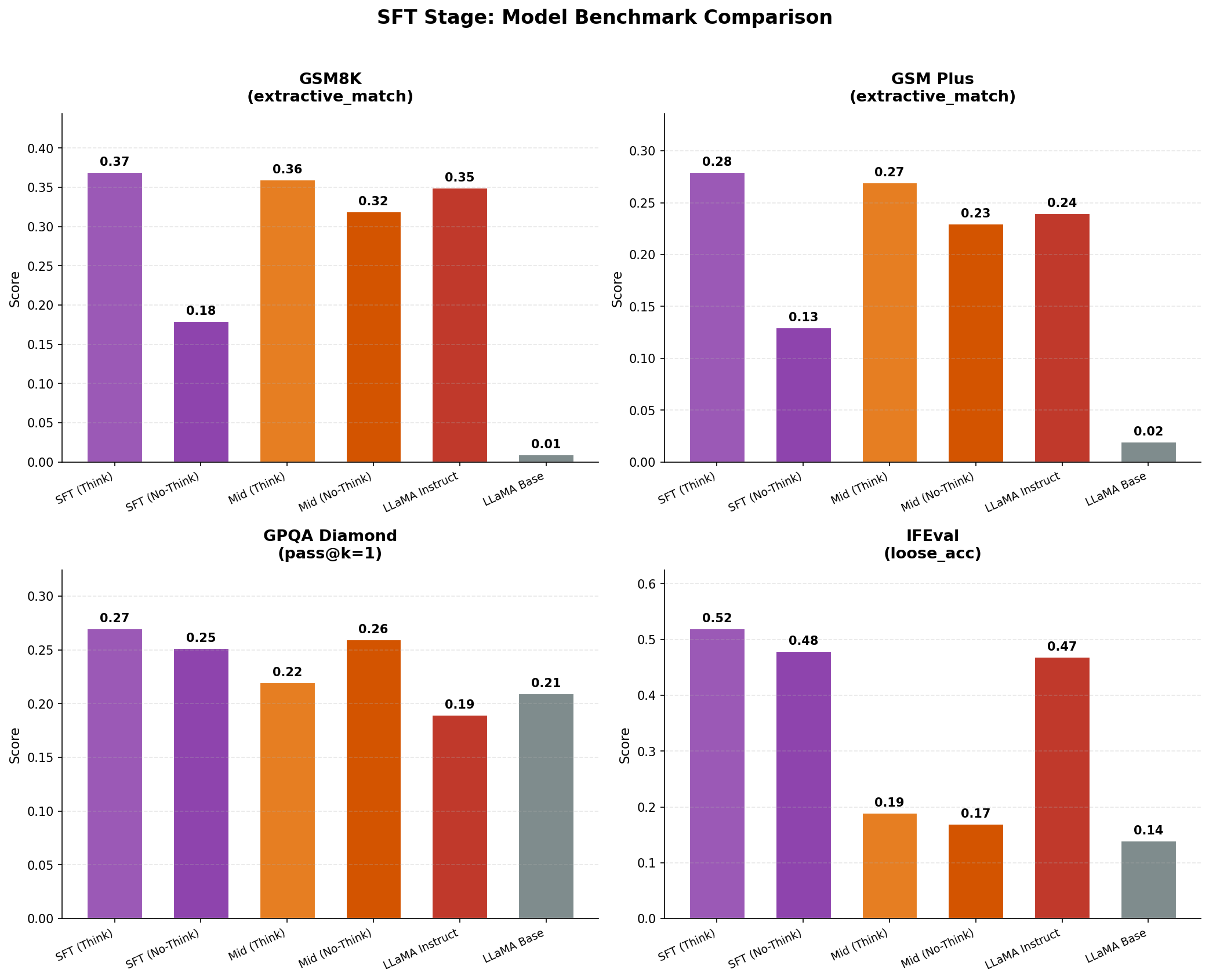
Benchmark Analysis: Comparing SFT to Mid-trained checkpoints:
- Primary win is instruction compliance: IFEval jumps ~3× (~0.15 → ~0.46), which is exactly what SFT is supposed to do.
- Math mostly preserved, not transformed: GSM8K and GSM-Plus improve modestly vs mid-training (e.g., GSM8K ~0.34 → ~0.36; GSM-Plus ~0.26 → ~0.28), so SFT didn't “create” math skill, and a good sign it didn't erase it.
- GPQA is flat (~0.26 → ~0.27): SFT changed assistant behavior more than it expanded knowledge.
- Interpretation: this stage looks like “format + helpfulness alignment” rather than capability injection; any future regressions are more likely from mixture/template choices than optimization instability.
Stage 3: Preference Alignment via APO#
To align the model's behaviour with desired responses (and avoid undesired ones), the next step was Direct Preference Optimization (DPO), using an Anchored Preference Optimisation (APO) variant for stability. DPO is an efficient alternative to full reinforcement learning with a human feedback reward model that directly trains on pairs of model responses labeled “chosen” vs “rejected”. The preference dataset used in SmolLM3 consists of 1B chosen-rejected pairs [10].
Although SmolLM3 maintained a max token length of 24576, we had to reduce it down to 8192 due to GPU requirements, as DPO-type objectives need to keep a copy of the reference model as well. It is also important to note that recent recipes have mentioned it is better not to do multiple epochs of DPO as it could overfit the model due to the nature of the loss function. We also noticed that a single epoch is enough during this stage. The DPO training configs can be found here.
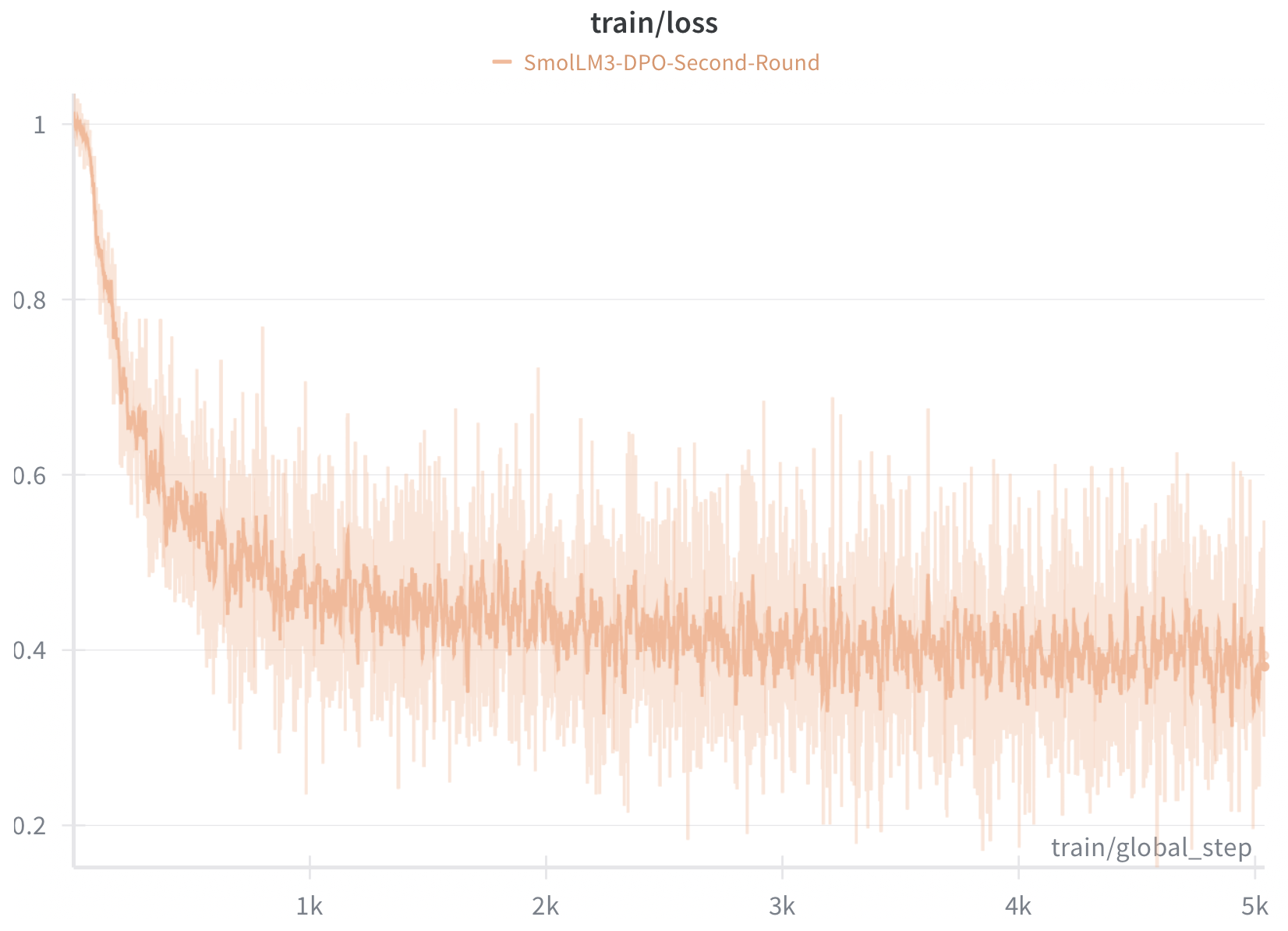
APO loss curve exhibits characteristic high variance typical of preference optimization. Starting around 1.0, the loss drops sharply to ~0.2–0.3 within the first 1K steps, then continues to fluctuate significantly throughout training. This volatility is expected, and APO's pairwise preference objective yields noisy gradients as the model learns to favor chosen responses over rejected ones, while anchoring implicit rewards to reduce drift from the reference model. The overall downward trend through 5K steps suggests continued learning. We stopped after a single epoch, consistent with the HuggingFace SmolLM3 recipe, and as a practical safeguard against overfitting to the preference dataset.
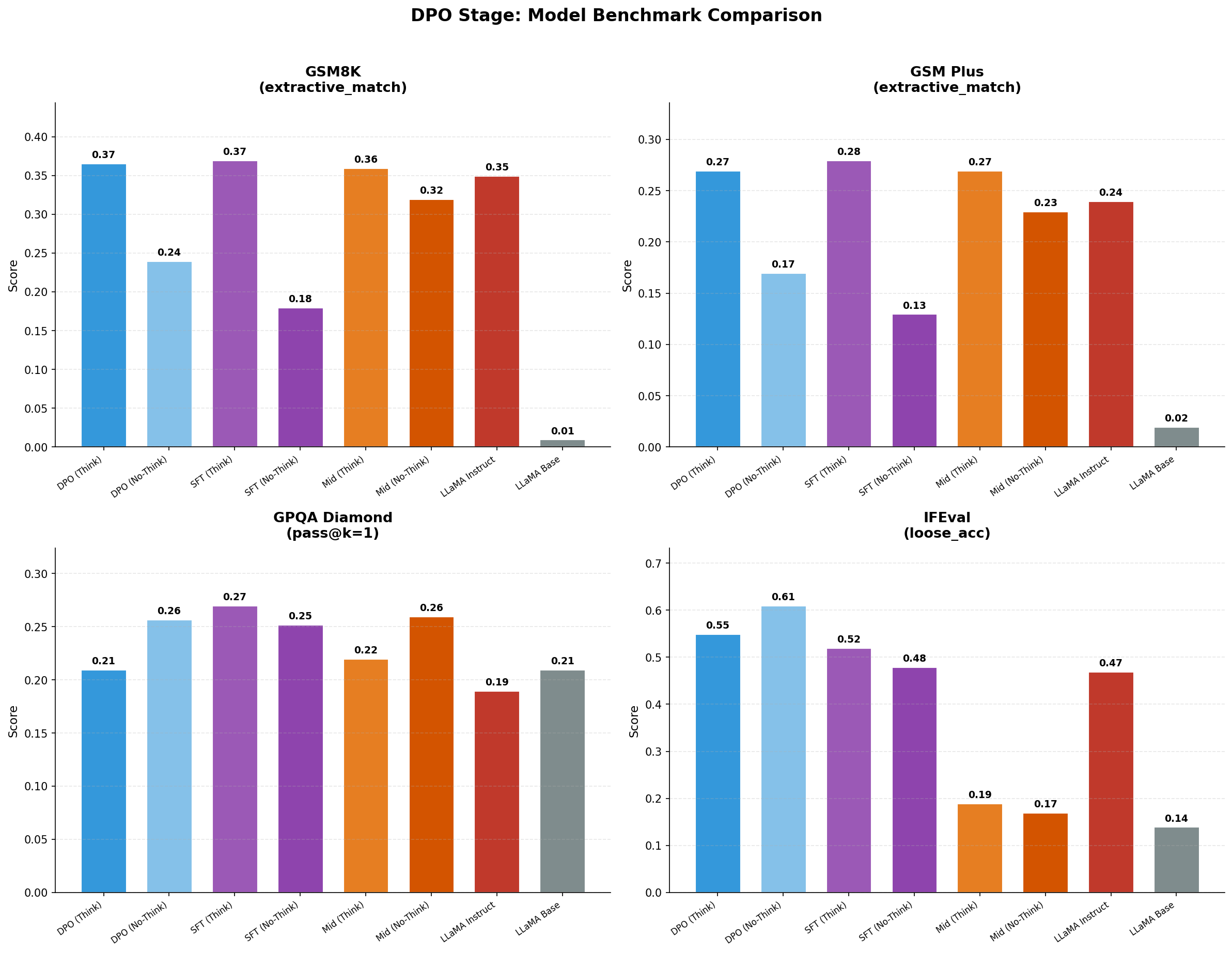
Benchmark Analysis: DPO/APO results show nuanced improvements:
- GSM8K is essentially unchanged vs SFT (Think): DPO-Think 0.37 vs SFT-Think 0.37 → no real gain; mostly preservation.
- GPQA is the clearest regression signal (especially in Think): DPO-Think drops to 0.21 vs SFT-Think 0.27. DPO-No-Think 0.26 is closer, suggesting the “think style” got worse for this benchmark.
- IFEval rises sharply, but it's for the DPO-No-Think: DPO-No-Think reaches 0.61 (higher than SFT-Think 0.52 and even Llama-Instruct 0.47). This could reflect preference shaping toward “format compliance,” not broader capability.
- Key confound (important for interpretation): During every stage, the datasets are a mix of long + short examples, and long examples trigger think behavior via an appended pattern. But DPO forced us to cut context from the original recipe (~21K) down to 8K (reference model overhead), so we had to remove long examples from the training dataset, as those were not fitting our compute budget. That likely reweights the dataset toward shorter/compliance-heavy samples and can distort think vs no-think comparisons, making DPO-no-think look strong on IFEval while being neutral/negative on harder reasoning (GPQA, GSM-Plus).
Stage 4: Reinforcement Learning with Verifiable Rewards (RL)#
The final and most challenging stage was Reinforcement Learning (RL) fine-tuning, aimed at further boosting the model's performance on complex reasoning and problem-solving tasks. While DPO had aligned the model on preference data, certain abilities – like solving difficult math problems or writing correct code – benefit from Reinforcement Learning from Verifiable Rewards (RLVR). Although there are different discussions around reward functions, loss functions, and methods, we decided to go with the most simplistic RLVR setup with sparse rewards, a GRPO style loss function and a verifiable (e.g., math) task schema, compared to most recent work [1,2].
Although recent RLVR datasets cover different domains such as coding and puzzles, we followed SmolLM3 and used open-r1/Big-Math-RL-Verified-Processed [11] dataset. This dataset consists of around 200K maths examples, with verifiable solutions. Next, another most important part is to pick a framework to conduct RL. After carefully reviewing frameworks like TRL [5] and NeMo-RL [12], we moved forward with the VeRL [6] framework, due to its stability and superior open-source support.
Unlike all other stages, this stage needed careful tuning of different functionalities given in the VeRL framework to utilise our given compute setup without getting OOM errors, at the same time without hurting the performance. Such parameters included number of samples per prompt, maximum sequence length, and the PPO batch size. We mainly followed this document from the VeRL team. In particular, we tuned the rollout batch size, number of responses per prompt, PPO mini-batch size, and GPU micro-batch size to balance learning stability, off-policy drift, and memory-safe throughput under our compute budget.
- Rollout batch (train_batch_size): prompts per PPO iter → stability + better grads
- Samples/iter:
train_batch_size × n_resp_per_prompt→ exploration + advantage quality - Mini-batch (ppo_mini_batch_size): samples per optimizer step → update smoothness vs noise. This is really important to maintain the stability.
- Micro-batch (*_micro_batch_size_per_gpu): GPU chunking → OOM safety vs speed (grad accumulation)
- Key tradeoff: bigger batches = stable/expensive, smaller = noisy/cheap
Recent algorithms tested (GRPO family and Qwen Team variants):
- GSPO (Group Sequence Policy Optimization): uses sequence-level likelihood ratios + sequence-level clipping (instead of token-level), aligning better with sequence-level rewards and reducing ratio noise, and especially important for long generations and MoE routing volatility [13].
- SAPO (Soft Adaptive Policy Optimization): replaces hard clipping with a smooth, temperature-controlled gate, down-weighting only clearly off-policy regions while preserving useful gradients from near-on-policy tokens [14].
- MiniRL-style correction (Qwen): emphasizes importance sampling / staleness control (keeping the ratio near 1) and decoupled clipping to suppress only unsafe updates, improving predictability and lowering gradient variance [15].
In practice, we did not observe large differences across GSPO / SAPO / MiniRL in our current setup: learning trends and final outcomes were broadly similar, with only small differences in convergence speed. We believe this is largely because we are training dense models in a highly synchronous VeRL pipeline, which already reduces rollout staleness and keeps importance ratios well-behaved.
That said, these techniques are expected to matter much more in MoE RL and in less-synchronous / higher-staleness regimes (e.g., larger-scale systems, longer rollouts, or expert routing drift), where token-level ratios become noisy and off-policy effects amplify. To support this, we also relied on VeRL's sampling/rollout correction module and followed their correction decision guide.
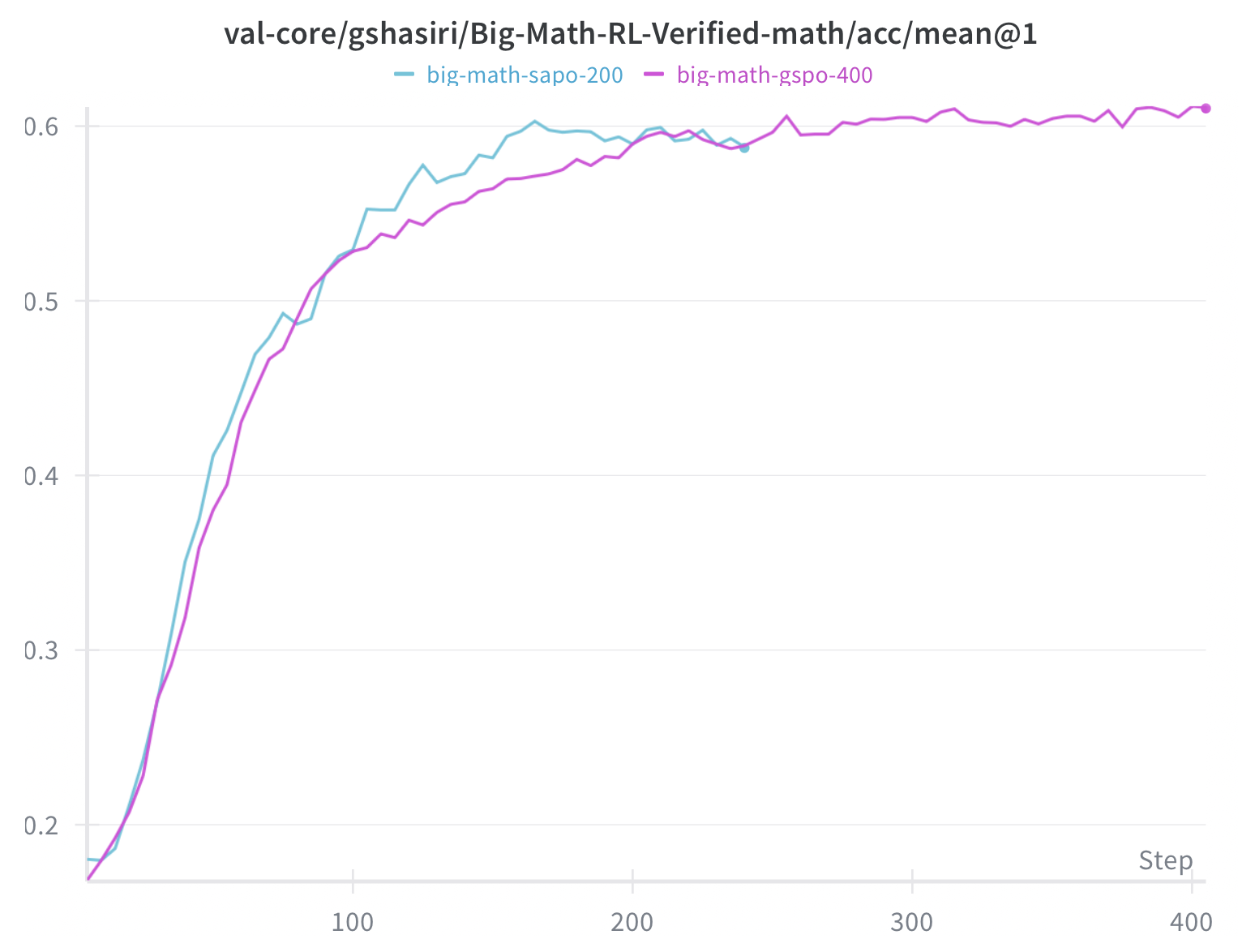
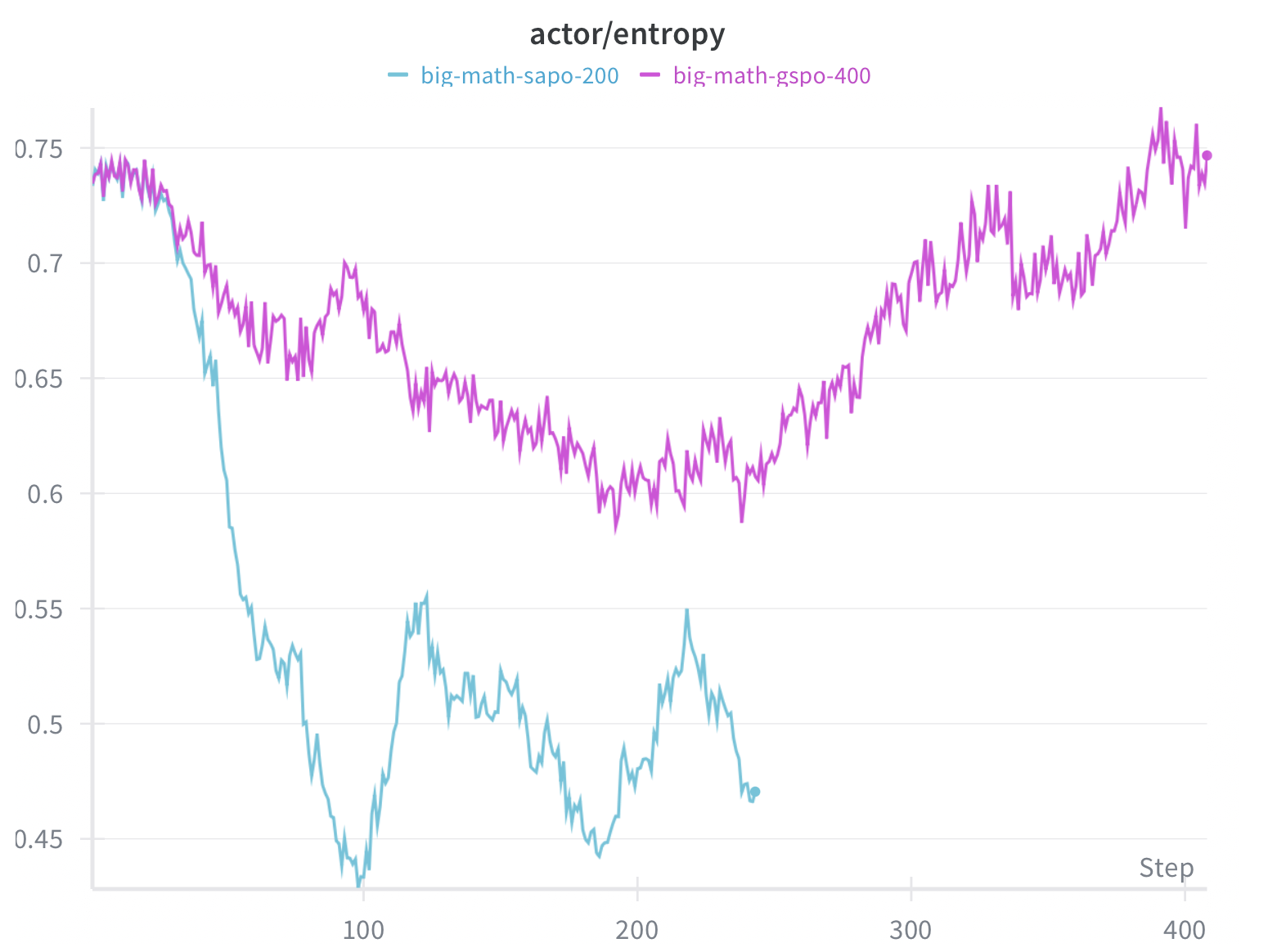
The reward curves for SAPO and GSPO variants both show strong upward trends from ~0.2 to ~0.6+ over 400 steps, demonstrating successful policy optimization. Both algorithms achieve similar final rewards, but GSPO (cyan) shows slightly faster initial learning in the first 100 steps. The continued upward trajectory at step 400 suggests further training could yield additional gains—a key insight that motivated our extended runs.
Entropy Curve Analysis: The entropy plots reveal important differences between algorithms:
- GSPO (cyan) shows a characteristic entropy dip from ~0.75 to ~0.45 around steps 50–200, followed by recovery to ~0.5. This “entropy collapse and recovery” pattern is typical of RL fine-tuning where the model initially becomes more deterministic before finding a stable exploration-exploitation balance.
- SAPO (magenta) maintains consistently higher entropy (~0.65–0.75) throughout training, suggesting its soft adaptive gating preserves more output diversity. This could be beneficial for generalization but may also indicate slower convergence.
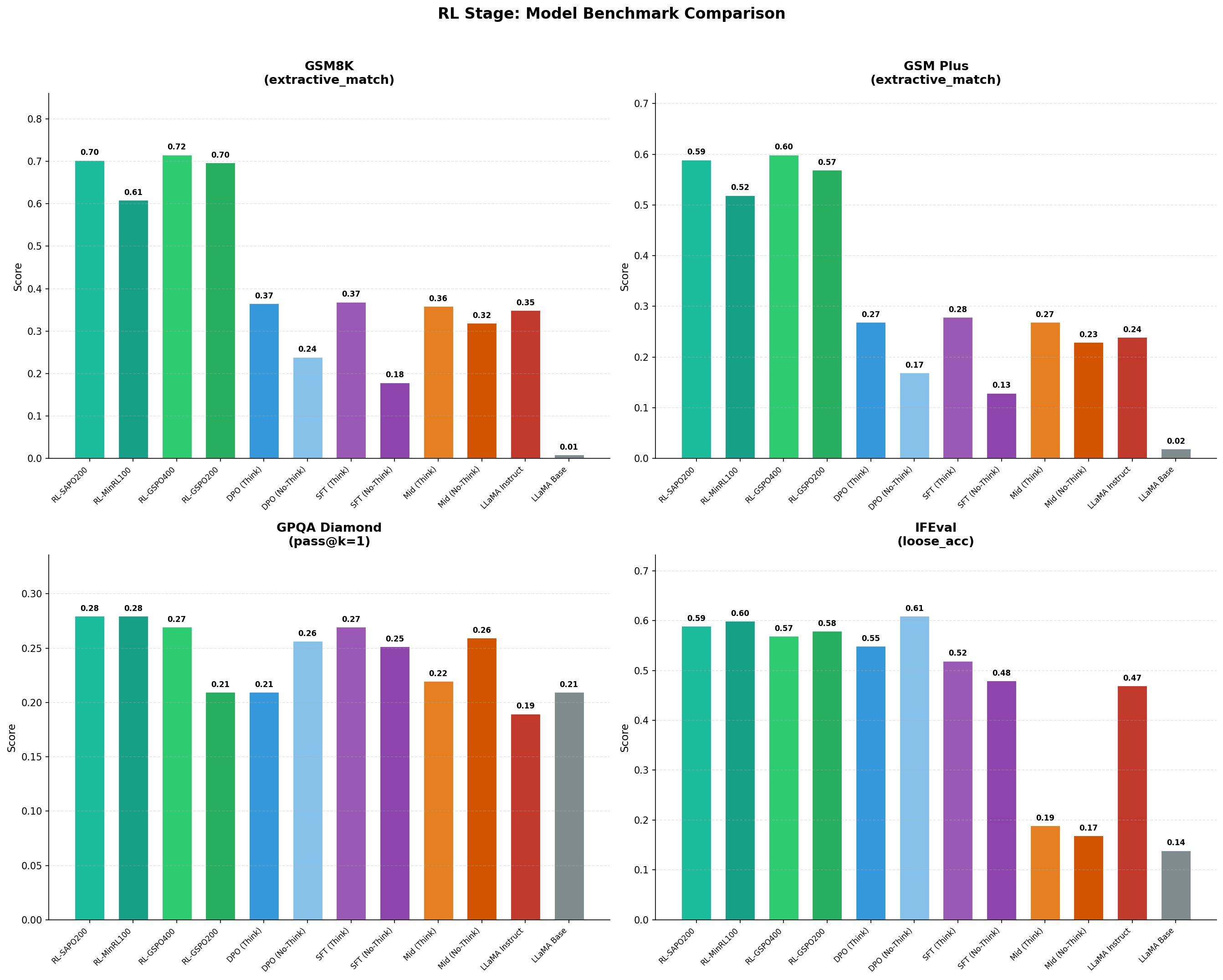
Benchmark Analysis:
We did a deep analysis on the RL evals, as it is still a green field.
Largest gains are on the tasks we reward (math):#
- GSM8K: DPO(Think) 0.37 → RL ~0.61–0.72 (e.g., RL_GSPO (400 steps) 0.72, RL_SAPO (200 steps) 0.70).
- GSM-Plus: DPO(Think) 0.27 → RL ~0.52–0.60 (RL_GSPO (400 steps) 0.60, RL_SAPO (200 steps) 0.59).
- This is the cleanest evidence that RL improves reasoning accuracy, not just “formatting.”
Non-math transfer is mixed (and sometimes flat):#
- GPQA: varies by run (0.21–0.28) and is not consistently higher than SFT (0.27) → expected because the RL reward/data is math-only, so transfer to science QA is limited.
- IFEval: remains high but doesn't clearly improve beyond DPO/SFT (RL ~0.57–0.60 vs DPO 0.55–0.61) → RL is not targeting instruction-following constraints, so it mostly preserves rather than improves.
Extended training evidence (steps really matter)#
- GSPO (200 steps) → (400 steps):
- GSM8K: 0.70 → 0.72
- GSM-Plus: 0.57 → 0.60
- GPQA: 0.21 → 0.27 (largest non-math recovery signal)
- IFEval: 0.58 → 0.57 (flat / slight drift)
- Interpretation: more RL steps keeps improving reasoning, but it does not automatically lift instruction-following, and can slightly drift without explicit preservation.
- RL_SAPO200 (GSM8K 0.70) vs RL_GSPO400 (0.72) both show the same story: RL roughly doubles math accuracy vs DPO, but algorithm/step differences make “winner” comparisons ambiguous unless matched.
Algorithm comparison (why variants can help)#
- GSPO: best headline math scores here (GSM8K 0.72, GSM-Plus 0.60 at 400 steps) → consistent with sequence-level ratio/clipping being a good fit for sequence-level rewards.
- SAPO: nearly matches GSPO on math (0.70 / 0.59) and is typically chosen when you want more conservative, diversity-preserving updates (soft gating).
- MiniRL correction: improves strongly over DPO (GSM8K 0.61, GSM-Plus 0.52) but is below the best GSPO/SAPO runs in this plot, still valuable as a stability-first baseline.
Why differences are not huge (in our setup):
- Dense model + relatively synchronous RL pipeline → lower staleness / saner ratios, so the fancy off-policy corrections don't dominate outcomes.
Why IFEval doesn't really move (and is this catastrophic forgetting?)#
- Likely not major catastrophic forgetting (IFEval stays high: RL 0.57–0.60). More likely: objective mismatch—math RL rewards correctness, not constraint-following style; so you don't get “new IFEval skill” unless you explicitly reward it or mix in instruction-focused objectives.
- The mild IFEval drift vs the best DPO checkpoint (DPO No-Think 0.61 → RL ~0.57–0.60) is a reminder that narrow RL can slightly reshape behavior.
Next iteration (concise suggestions to add)#
- Model merging as a safety valve: merge an RL checkpoint with the best SFT/DPO checkpoint to recover “assistant behavior” while keeping RL math gains (particularly useful when RL is domain-narrow).
- Broaden verified domains: add verifiable code/unit tests or logic tasks if we want RL gains to transfer beyond math.
Lessons Learned#
We conclude this single-node post-training journey with a clear takeaway: Mid-training and SFT reliably shape priors and instruction behavior; DPO/APO offers smaller, sometimes unstable, deltas under tight context constraints; and RL is the only stage that consistently produces a step-change in verifiable reasoning given we already have a solid model that has seen MID, SFT, and DPO data, albeit at disproportionate compute and tuning cost.
Stage-Specific Insights#
Each training stage has its own failure modes and success signals. Understanding these prevents wasted compute and silent regressions.
- Mid-Training establishes the foundation. High-quality reasoning-heavy text mattered more than raw token count. The key lesson: loss plateau alone is a weak stopping signal—track downstream metrics instead, because the model can still be improving on tasks even when loss flattens.
- SFT shapes assistant behavior. Mixture diversity prevented capability collapse, and template quality strongly affects outcomes. Stop when IFEval saturates and reasoning metrics remain stable—but watch carefully for hidden regressions that only surface later.
- DPO/APO is where things get fragile. Over-optimization risk is high (typically one epoch is enough), and context constraints can distort the objective entirely. Our forced context reduction from 24K to 8K—due to reference model memory overhead—required removing long examples, which biased the dataset toward shorter, compliance-heavy samples. This likely explains why DPO-No-Think excelled on IFEval while showing neutral-to-negative effects on harder reasoning benchmarks.
- RL delivered the largest single-stage improvement. GSM8K roughly doubled compared to pre-RL checkpoints, and performance continued improving with additional steps. However, RL rewards are narrow by design: math-focused RLVR produced real math gains but didn't reliably lift GPQA or IFEval. If you want broader transfer, those objectives must be explicitly included.
Critical Success Factors#
- Evaluate for drift, not just benchmark scores. The main risk isn't underperformance—it's catastrophic forgetting and objective drift. We ran automated evaluation (LightEval) on every checkpoint, tracking at minimum: one reasoning metric (GSM8K/GSM-Plus), one instruction metric (IFEval), and GPQA as a transfer canary. This caught early SFT regressions that would have been invisible from loss curves alone.
- Data quality beats data quantity. This held across all stages. Mid-training benefited more from curated reasoning data than from scale. SFT needed mixture diversity to prevent collapse. DPO required preference pairs with clear quality separation—subtle differences between chosen and rejected samples produced noisy gradients. RL datasets with verifiable rewards gave the cleanest signal.
- Memory constraints materially change the experiment. We used ZeRO-3 throughout, enabling 32K context for mid-training and 65K for SFT with gradient checkpointing. But DPO's reference model overhead forced an 8K context limit, fundamentally altering our data distribution.
The Power (and Pain) of RL#
RL is worth the investment: it's the only stage that produced genuine step-change improvements in reasoning accuracy, not just formatting or compliance. The continued upward trajectory at 400 steps suggests we hadn't yet saturated, and more training likely yields more gains.
But RL remains a “green field” for practitioners:
- Algorithm choice matters less than expected in our setup. GSPO, SAPO, and MiniRL produced broadly similar outcomes with small convergence-speed differences. We attribute this to our dense model and synchronous pipeline, which naturally keeps importance ratios well-behaved and reduces rollout staleness. These techniques likely matter more for MoE architectures or less-synchronous regimes.
- Entropy dynamics are your early warning system. GSPO showed characteristic entropy collapse followed by recovery; SAPO maintained higher entropy throughout. Monitor both entropy and reward together—entropy collapse without recovery signals trouble.
- Practical tuning philosophy: Start conservative with batch sizes and KL constraints. Checkpoint frequently. Compare algorithm variants empirically on held-out benchmarks, not just reward curves.
Compute Reality Check#
Mid-training, SFT, and DPO are relatively cheap compared to RL. If compute-constrained, get the earlier stages correct first—they establish the foundation that RL builds on. Then allocate remaining budget to RL, where the returns are largest but the cost is highest.
For context, our single p4d.24xlarge node (8× A100-40G) completed the full pipeline, but RL alone consumed more wall-clock time than the other three stages combined.
References#
- Hugging Face. SmolLM3 Training Playbook: Modifying Your Baseline – The Discipline of Derisking.
- Olmo, Team, et al. (2025). OLMo 3. arXiv:2512.13961.
- Meta AI. Llama-3.2-1B. Hugging Face.
- Meta AI. Llama-3.2-1B-Instruct. Hugging Face.
- Hugging Face. TRL: Transformer Reinforcement Learning. GitHub.
- Volcengine. veRL: Volcano Engine Reinforcement Learning for LLMs. GitHub.
- Hugging Face. SmolTalk2 Dataset. Hugging Face.
- Hugging Face. SmolLM3-3B Mid-Training Chat Template. Hugging Face.
- Hugging Face. SmolTalk2 – SFT Split. Hugging Face.
- Hugging Face. SmolTalk2 – Preference Split. Hugging Face.
- Open-R1. Big-Math-RL-Verified-Processed Dataset. Hugging Face.
- NVIDIA. NeMo RL. GitHub.
- Zheng, C., Liu, S., Li, M., Chen, X.-H., Yu, B., Gao, C., Dang, K., Liu, Y., Men, R., Yang, A., Zhou, J., & Lin, J. (2025). Group Sequence Policy Optimization. arXiv:2507.18071.
- Gao, C., Zheng, C., Chen, X.-H., Dang, K., Liu, S., Yu, B., Yang, A., Bai, S., Zhou, J., & Lin, J. (2025). Soft Adaptive Policy Optimization. arXiv:2511.20347.
- Zheng, C., Dang, K., Yu, B., Li, M., Jiang, H., Lin, J., Liu, Y., Lin, H., Wu, C., Hu, F., Yang, A., Zhou, J., & Lin, J. (2025). Stabilizing Reinforcement Learning with LLMs: Formulation and Practices. arXiv:2512.01374.